Published Alex Hodgson on April 1, 2020
If you’ve been following VUV for a while, you’re no stranger to Time Interval Deconvolution† or TID™ for short. We’re certainly not shy about touting its strengths in allowing us to compress chromatography and shorten run times! In this installment of , we’ll rehash the basics of TID and discuss how we use it to such great success in our applications.
For those new to the concept, time interval deconvolution is an alternative methodology for quantitating chromatographic data. Traditional chromatographic quantitation methods using both analog (e.g., FID, TCD) and spectral (e.g., mass spec) detectors integrate area under peaks to determine concentration. While this approach is fine for well separated peaks, any significant coelutions must be addressed by arbitrarily splitting the two (or more) peaks at a certain point, cutting off a non-trivial amount of each peak.
And this is where TID comes into play: regardless of the acquisition frequency, we can sum the absorbance spectra for a given time interval and match that spectrum to the reference spectra in our VUV reference library. Sometimes the acquired spectrum will match perfectly to one of our library spectra; other times a single-analyte match won’t cut it, and so the software will search for the best multi-analyte combination (Figure 1). Either way, the total spectral response of each contributing analyte is banked. Once all the time intervals have been matched and the total responses banked, we can then apply relative response factors and densities to convert those responses to a relative mass % and/or volume %.
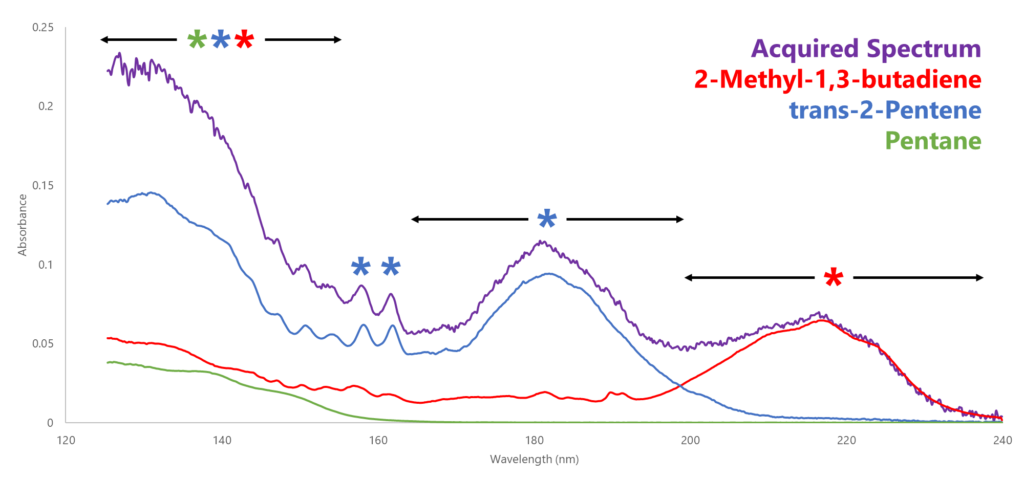
Figure 1. Because all our quantitation is first order (thanks to Beer’s Law), the acquired spectrum is simply the sum of a linear combination of multiple contributing analyte spectra. The area under each contributing spectrum is the spectral response of its corresponding analyte.
So how do we apply this to some of our major applications like D8071 (Gasoline), D8267 (Jet Fuel), or VHA™? Once we’ve bucketed the total response for each library compound we’ve found in our chromatogram, we can report that data however we want. For a method like D8071 where our focus is classing by hydrocarbon type (i.e., PIONA), we want to assign everything to one of those five categories first and foremost; from there we can call out some individual species as we see fit. VHA is simply a more stringently controlled version of D8071 from a quantitative standpoint, since we’re also adding “Analyte to Include” time windows for additional confidence in our speciated data. For D8267 we only want much broader categories like saturates, mono-aromatics, and di-aromatics; we can also sum the mono- and di-aromatics to give us total aromatics. We can even use it for non-fuels applications, such as characterizing terpene content of essential oils or FAME (fatty acid methyl ester) analysis of foods!
How has TID saved you time and energy in your data analyses? What other applications could use the power of TID? Let us know in the comments, and stay tuned for more VUV 101 lessons!
References:
†LCGC Blog from Kevin Schug on June 1, 2017
Author

Alex Hodgson
Alex Hodgson is an Applications Chemist at VUV Analytics, Inc. His current research focuses on vacuum ultraviolet applications for the flavor and fragrance industries, among a variety of other VUV-related endeavors. Prior to coming to VUV Analytics, Alex was a member of the Center for Disease Control’s team in Atlanta, where his research was on tobacco exposure biomarkers. He earned a B.S. in biochemistry from the University of Texas at Austin and an M.S. in biochemistry at the Georgia Institute of Technology.
One response to “VUV 101: Time Interval Deconvolution”
Leave a Reply
Related Reading

Verified Hydrocarbon Analysis: Synergy Between DHA and VUV
Ryan Schonert
In this blog, Ryan talks about the many benefits of the Verified Hydrocarbon Analyzer as…
Read More >
Exploring the Data View Window in VUVision™ Software Part 2
Chris Cook
This blog is the second part in a three part series on the VUVision Data…
Read More >
Obtaining Quality VUV Spectra using VUVision Software
Chris Hernandez
This blog outlines what must be considered when adding a compound to your user library…
Read More >




I like this approach ! The TID result can be perfect input for the StillPeaks D86 model, a popular solution for refinery labs !